Effective Code Freezes in a CI/CD World
Here at REI, we take site reliability seriously. But as a company with an extensive CI/CD stack we want to be able to make changes and deploy as needed. Sometimes, there can be conflict between these two ideals; we want to prevent breaking changes while still allowing continuous delivery.
To help combat these issues, we built an internal tool called Ranger Station that will ‘freeze’ critical git repos during sales, major events or high risk periods where we are expecting lots of traffic. We use ‘freeze’ here as a very loose term. It’s more of a ‘soft freeze’ where we still allow commits and changes – we just require an extra set of eyes on that code to be sure we don’t break code in production.
Ranger Station isn’t a brand new tool for us, in fact we’ve had versions of it in use for a few years, and its development has been primarily driven by our summer interns (Hey, I was one of those!). Before we built Ranger Station, we had an ugly and painful change approval process to jump through if we ever needed to push to production during a code freeze. This would typically entail a hard code freeze from November through January during our major sales of the year. If a change needed to go through during this time, we had to have lengthy discussions with multiple managers and it could take days to get an “emergency” change into production. Even low risk changes had to go through this same process. But now with Ranger Station, it’s streamlined, automated and it ensures we can safely get code pushed out in a timely manner.
Original Implementation
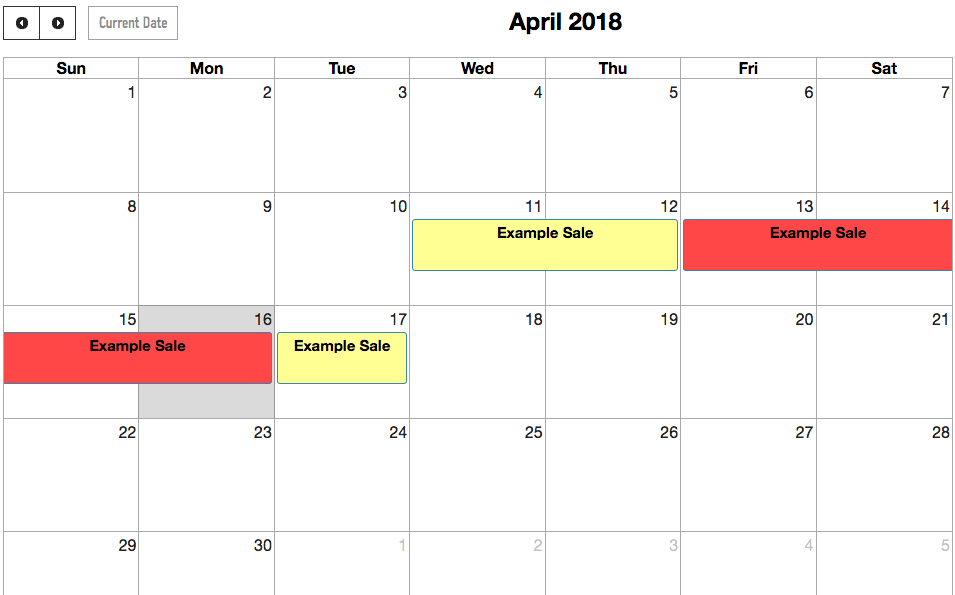
On its homepage, we show a calendar view with any upcoming freeze dates and their freeze level (graded on how significant the event is for us: red for the highest expected demand, yellow for more-than-normal demand, green for typical days). Originally when a freeze came, Ranger Station would apply code freeze rules to all of our git repos on an opt-in basis for apps using our Alpine Platform. This meant that all Pull Requests were required to be approved from someone in one giant list of approvers that applied to all applications. Once a freeze was in place for a day, it would send a notification to a Slack channel stating the current freeze level.
With Ranger Station’s original implementation, we noticed two major issues:
- One master list of managers to approve pull requests isn’t very useful! Developers working at our other campus or in a separate department were asking for approvals from managers that have never seen the code or weren’t even familiar with the details of that app.
- Opt-in freeze management of applications isn’t ideal. As the number of microservice apps grows, it becomes harder to ensure that all critical apps are protected on sale days. Out of the 100+ microservices using the Alpine platform, less than half opted in to Ranger Station.
Who Should Approve?
We first set out to find ways that we can make approvers more relevant and less like meaningless hurdles for every developer. Our solution was to have Ranger Station manage groups of relevant people and to require every app to use one of those groups. Each tier would have two sets of people that would approve: High Level which would be managers or directors, and Standard which should be senior devs and project leads – people that understand the code. The freeze level, either Red or Yellow, would determine which to apply for the day for each app.
Application Tiers
Those approver groups were able to make deciding who should approve a lot easier, but we also needed to find a way to determine which apps are even worth managing with Ranger Station. In our system, there’s a variety of levels of app importance. For example, everything that runs the customer facing rei.com website – that’s pretty important! But internal tools like Ranger Station itself? Downtime obviously isn’t desirable, but it doesn’t directly touch anything in the customer purchase path. We even have less-critical apps that could be experiments, demos, or just temporary projects – downtime for these doesn’t matter too much.
To handle these varying levels of importance, we decided to make it a first class property in our app configurations and to be reusable beyond the scope of Ranger Station. We defined this ‘app tier’ system as explicit categories that describes how critical each app is for the customer experience.
After adding this tier we can easily determine which apps get which approvers on sale days:
| Tier | Red Day | Yellow Day | Green Day |
|---|---|---|---|
| Customer Critical | Management | Senior Devs | - |
| Supporting Systems | Senior Devs | Senior Devs | - |
| Internal Tools | Senior Devs | - | - |
| Experimental | - | - | - |
| Undefined | Blocked | Blocked | - |
As you can see, the most important systems require management approvals on red days, while other apps can be less strict. This also allows us to get rid of the opt in system we had before and enforce rules for all applications. To get all the applications and teams on board with these new changes quickly, we defaulted every application to have no tier or approvers until the maintainers explicitly provided them. That way they are effectively frozen until they are set on a red/yellow day.
Other improvements
Since these changes were a significant bump in complexity of Ranger Station, we created a dashboard on Ranger Station that lists the current day, the freeze level, and all the apps that were frozen and their approvers. This way developers can see a summarized view of the day and any necessary changes they may have to make to their workflow to get code approved.
We created a general slack notification that links to this dashboard and is sent by our internal Slack bot, Ranger Smith. In addition, we also set up per-app notifications so that Ranger Smith can notify each team of the specific approvers for the days in their own channel that they define.

Wrap Up
It’s hard to find a good balance between Continuous Delivery and Code Freezes, but Ranger Station has been a great tool to help us figure out how we can automate and control that balance during some of our higher risk periods.




