Introduction to Chaos Engineering
Does the thought of being oncall for a critical service keep you up at night? (Or do bears?)
Customer scenario
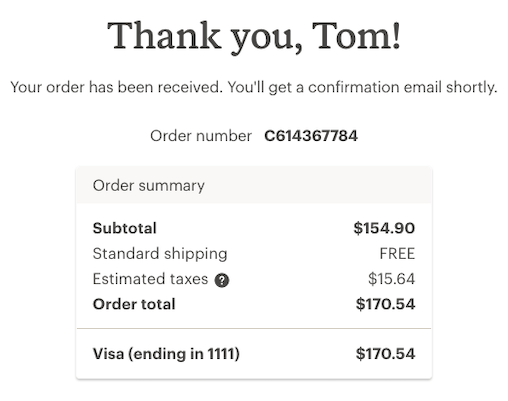
Let’s say you had a great day walking around the zoo. Say hello to Huckleberry. Or is it Hawthorne? Does it matter? Look at those claws!

The thought of meeting either one in the wild keeps you up all night, so you decide to do some shopping.
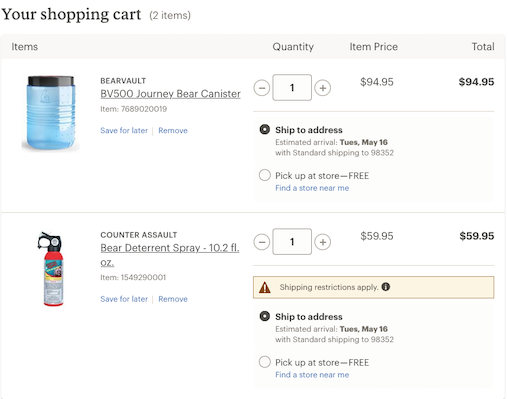
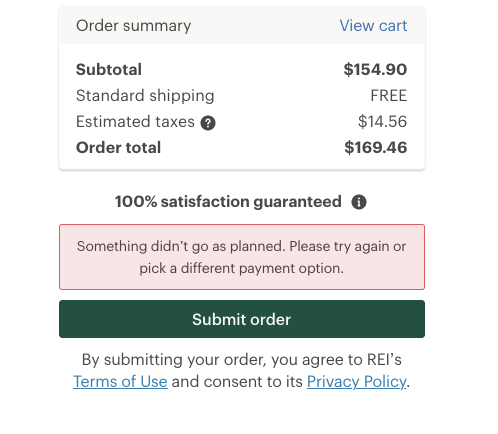
Clicking submit order and ready to go back to bed. Wait a minute - didn’t go as planned?
Engineer scenario
You’re the oncall engineer supporting REI’s shopping cart & checkout and you get an alert in the middle of the night that some service (xxxService) is throwing errors. After dialing into the major incident conference call you are asked what is the customer experience when xxxService is unavailable? Panic time, right? Good thing the camera is off!
REI’s Checkout microservice orchestrates numerous dependencies to provide shopping cart and checkout functions for rei.com and mobile apps. For example, Customer Info, Dividend, Gift Card, Credit Card, Coupons, etc. With so many dependent services, it’s inevitable that something will break at some point. The goal is to minimize the customer impact during checkout.
Purposefully fuzzy relationship image
Chaos Engineering to the rescue?
Chaos testing is just one of the many types of testing we do at REI to ensure our services are working properly.
From Principles of Chaos Engineering:
Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
There are many types of tests that you can do that could fall under the umbrella of Chaos Engineering. For the purposes of this article, I have focused on testing individual services going down.
Game day scenario
This works best with the whole team present: Developers (frontend & backend), architects, SDETs, product managers, etc.
- Hypothesis - What happens when the xxxService is unavailable?
- Test - Disable xxxService. Since all of our services are invoked using the Resilience4j circuit breaker, this is achieved by putting the breaker into “Open” state. We did this in our test environment. You could also change the read timeout to 1ms, or use Wiremock or something similar to respond with a 5xx error. Side note - we’ve migrated from Hystrix to Resilience4j. See excellent article from Jeremiah Pierucci here.
- Observe - Did it behave the way you expected? While going through the exercise, sometimes the hypothesis did not match what we observed, and we needed to make some change to address it. In other cases, the website did not behave the way we wanted it to. Doing this live with the whole team was very enlightening for me, as we sometimes had different ideas of how the site should behave (For example, what happens when xxxService is not available - should it block customers from submitting their order? What should the user experience be?)
- Fallback - do we want to add a fallback response when any of the services are down?
- Document - With so many dependencies it is important to document the expected behavior (otherwise I won’t remember at 2 am when I am oncall)
Continuing the Chaos journey
This testing is not intended to be done one time only - you will need to be diligent when new services are added, and it would make sense to repeat these tests on a semi-regular basis, as other parts of the code could have changed.
The experiment described above can be thought of as a building block of Chaos Engineering. As you gain confidence in this testing, you could increase scope to include things like database, cloud infrastructure, spikes in traffic, or really anything you can think of that could disrupt your service. Eventually, as your Chaos Engineering practice matures, you could automate these tests and add them to your build pipeline, and perhaps eventually test in production.
Hopefully, the result is that both customers and oncall engineers sleep well at night. You do have robust monitoring and alerting for your application, right?