Unlocking Continuous Deployment
We have been practicing continuous deployment for a while now. At this point it is entrenched in our culture and our tools and almost difficult to remember our workflow prior to the switch. Of course, “switch,” is not quite the correct word for it. While there was an exact point where we cut over and enabled the flow, it required years of persistence, iterations, determination, convincing, and development. Being an established retail organization, sending changes to our high-traffic e-commerce site into production several times a day was a difficult concept to sell.
“You’re crazy.” “That can’t happen here.” “This place is too old school.” “That stuff is for start-ups and tech companies.” All of which are direct quotes from people at REI when we first started to suggest the idea. To be fair, we were not in any place to actually do it at the time, but the motivations behind the suggestions were simple. We wanted quick, reliable, and low-risk delivery of our valuable digital properties. We wanted fast cycle time and small change sets with quantifiable risks. We wanted to optimize our time to market while still producing high-quality software with low to no production incidents. We wanted to validate our decisions incrementally before syncing the full cost of development. We wanted a highly automated build, test, a deployment system. Most importantly, we wanted a high-performing technical team and an engineering culture that thrives on continuous improvement.
Conceptually, deploying continuously (or at least more frequently) was an easy sell. The value proposition was clear and largely supported by most everyone in our development shop. It was the path forward that was hard to comprehend. We had some processes and tools that were not real conducive to this way of working. Additionally, our team structure and technical architecture also added a certain level of complexity and uncertainty. Making significant cultural changes in a large group of people with years of established practices and tools was no easy task. It was a big ship with a small rudder and the only way it was going to turn was with continual and consistent pressure… and even then would be slow. As it turns out, however, we had a few key elements that we were able to use to make the cultural shift happen more swiftly at key points, thereby fast-forwarding us to a new level of maturity.
A Little History
Before getting into the secret sauce that we used to make continuous deployment happen I want provide a little context and history. For this we must travel back in time roughly six/seven years (2011-ish). At that time we had about 150 people contributing to our e-commerce site in some way. That number consisted of 40-50 developers plus QA, UX, and other key players. Our application was a large monolith with roughly 500,000 lines of Java code, a large amount frontend code consisting of varying frameworks, and a separate, yet coupled, collection of static frontend and marketing resources required to actually run the application. The going joke around our development shop was the codebase was like a code museum where you could find elements of whatever framework was hot over the last decade.
We worked under the Scrum methodology and ran three week sprints. Developers contributed to the single codebase throughout the day and every night we would produce an artifact that would get deployed to the QA environment for testing. At some point in the third week of the sprint we would create a “release” branch of the code that would then be installed in the QA environment until it was “certified” by our quality assurance team. The certification process took roughly 4 days, during which time we had to patch in bug fixes off of the main code line into a branch. It was manual and tedious. No new code or features unrelated to what was being certified was allowed into the QA environment during this time. If the build actually got “certified” we would then go to the Change Approval Board (CAB) for approval to deploy to production. Deployment would happen the following Monday, which took a large part of the day and required coordination with various people in different roles and some amount of manual intervention. We would maintain the release branch with any necessary fixes until the end of the next sprint where we hopefully had a new build certified that we would deploy. Any patches to the production system during the sprint went through a similar process of certification and ceremonial deployment. If all went well, we had the opportunity to deploy new work (as opposed to bug fixes) to production roughly once a month. In reality, taking into account freeze periods and un-certified builds, we only deployed to the production site maybe 6-9 times in a year.
The process described above is an overly simplified summary of how we were working six+ years ago. The description above was even after some amount of work to speed up the process already. You can probably spot the areas of improvement right away and where we needed to focus. One thing about that time that was interesting was there were so many quick wins to be had, which allowed us to build up a good reputation that we were able to leverage later on when the cultural issues were much harder to solve. There were many issues with our workflow back then, but probably the most troubling was the feedback loop and which groups felt the responsibility for quality. Adding automated tests and a pipeline were among the first steps that evolved from there. As we continued to resolve issues we were able to ratchet up our velocity a bit. Going from far and few between to weeks, then weekly, daily, and ultimately continuously.
The Continuous Elixir
Given the history above you can probably imagine the road to continuous delivery was not for the faint of heart. Changing the minds and process of a culture was and is difficult. Thinking back, there were a few key ingredients to our success. While each of these items had many factors, we can essentially distill the secret sauce into three primary buckets: 1) Leadership; 2) Our platform engineering team; and 3) Tools.
Leadership
Without question one of the keys to our success was our leadership. They got excited and ultimately empowered us to try new things. The management team was also instrumental in driving expectations and making this type of work part of our system. In one case we were struggling getting changes through the pipeline due to a variety of factors. I believe we were doing daily deployments at that time, but had gone a week or more without an actual push to production due to these issues. To break this cycle, our leaders brought together a group of people for an off site value-stream mapping session that spanned several days. Without doubt this was an expensive meeting, but one they felt was necessary for us to level set and best understand the problems we were facing. They created a safe environment for open discussion where the group was able to identify, speak to, and ultimately resolve some of the key issues that were inhibiting our flow. Ultimately we came out of that meeting with tactical steps to implement continuous delivery.
Good engineering is not enough. To make this work there needs to be strong leadership that understands the value proposition for continuous delivery very clearly, is able to articulate it to other teams, and is willing to give the engineers freedom to solve the problems at hand. Leaders are essential to help shape a safe culture that is built on trust and transparency. One that thrives on continuous improvement and is always striving to push the bar forward. In our case, the leaders over our digital division completely backed, staffed, and funded our teams accordingly. One team in particular is the second ingredient to the continuous elixir.
Platform Engineering
At REI we have a team of engineers dedicated to development of platforms, frameworks, tools, etc. This team is primarily made up of software engineers, but has a close relationship with other skilled groups. For example, our Database and Middleware, Network, and Server Engineering teams have all developed close relationships with the platform team and are essential to tying the pieces together. We have specific people on those teams that have become specialized and know our digital space quite well. For a long time, we had several Linux/middleware experts on loan and embedded with the team. These individuals sat with the platform crew and worked almost exclusively on platform related work. The power of this skill set in conjunction with the others on the team made for a powerhouse of productivity. So much so that it ultimately led to one individual making a permanent home with the team.
It just so happens that the individuals on the platform team are persistent and excited about devops, lean software development, data, and continuous delivery. That consistent pressure mentioned above, well… that was this team. Of course there were other advocates and enthusiasts spread wide around our development shop and people that played key roles, but this team was in place and had specific funding for development of tools and frameworks. Given that, the Platform crew was able to provide that consistent pressure, speak to the value proposition, spread the excitement across the organization, and most importantly build or install any necessary tooling.
Tools
The tools we built and installed over the years are the real driving force behind our continuous delivery efforts. They are what allowed us to make cultural changes more swiftly and bring us to a new level of maturity in our journey. We have always had this notion of changing or shaping the culture through tools. Our thought was to make the desired behavior easy and people will follow the path of least resistance. Of course implementing a new tool, technique, or process came with some level of churn in itself, but the development teams ultimately embraced the changes and were happy with the outcome. It always made me smile when the new process became the standard that was then expected. For example, once we went to a new deployment frequency, it quickly became frustrating if we could not meet that frequency for some reason or another. Teams began to expect and rely on that cadence.
For the sake of brevity, I will not cover all of the tools and process changes we developed or installed to support continuous delivery in this article. There will be dedicated writings in future blog posts about specific items. In this context, however, I do want to provide three of the clutch items that I feel are significant turning points for our course. In general our motivation for any tool or process we developed or installed was directly tied to these objectives:
- Tighten the feedback loop
- Optimize for time to detect and time to recover
- Prevent large-scale changes
- Minimizing the blast radius
Going beyond those easy and quick wins I mentioned in the brief history above, one of the hardest transitions for us was going from a weekly cadence to daily. To make this leap, we happened to leverage a long standing project that was about to launch. That particular project team was anxious about the cadence and wanted the ability to more rapidly adjust to any issues that popped up. Even beyond bug fixes they wanted to be able to adjust to a/b tests or other user-centered optimizations. This was perfect and gave us the ideal opportunity to suggest deploying to production daily instead. Of course that was not without challenges. The concern quickly went to how that would work in practice. At that time we deployed one monolithic application that many teams contributed to. There were serious trust issues across the teams. It was not uncommon for one team to be concerned about another team breaking them. The answer to this, of course, was automated tests, but even beyond that there was this fear of the unknown. The solution: a new tool.
Thinking back now, this concept was somewhat silly, but this changed the culture. It built trust and confidence among the teams. Moreover, it taught people to value and desire smaller change sets. The tool was something we referred to as a “release vote,” which was a simple web service and page backed by a database that would aggregate information about the application for display and provide a big, red “veto” button. The release vote would remain in this pending state for some amount of time where people could review the information, test out the application in a staging environment, and then optionally hit the “veto” button. If the allotted time elapsed without a veto/cancel then it would then automatically progress into production. It really was not a vote at all so I am not sure why we called it that. It was really just a quick preview of what was about to go with an opportunity to cancel. Everyone was notified of the pending changes and everyone was able to cancel. On the “vote” page people could find a list of changes, test result status, as well as some detail about the types of changes and what part of the application was touched. The real power of this simple, yet effective tool was that it provided a nice little history in the database for what changes went live when or why builds were being canceled. It also provided a nice little view into the size of the change sets, which later helped us ratchet the deployment cadence even more. People started to value reviewing smaller and smaller “vote” detail as it made it more clear what the impact of the deployment will actually be. It was great to see people really question and push on each other when a deployment opportunity was missed as this just resulted in yet more change piled on. This process evolved over time. It got simpler and more streamlined as time went on. To this day we still have the concept of a cancel button, but with far less ceremony.
At the beginning of this effort our site was just one monolithic codebase and one pipeline or path to production. We started to see contention in the pipeline and concerns from groups about how the testing environments were used. We used the branch-by-abstraction technique to hide in progress work, which were often toggleable through some configuration value. Teams had the desire to have their feature on for testing and sharing. There were only a couple of shared non-production environments at the time and this caused a little churn as different teams were trying to develop features. Again, the solution was a new tool, which later we found to be pivotal in enabling continuous deployment. It was this concept of a “try environment.” We actually got the name for this from Etsy’s codeascraft blog. The concept was, and is, wildly popular among our dev teams and is still one of the most widely used items in our bag of tools. Try environments allow developers to create a branch of their work and deploy it in isolation to a remote and fully functional environment. Changes in a “try” branch go through a mini pipeline with many of the same steps that it will go through in the main production pipeline, including execution of the automated test suites. As a “try” branch works through this mini pipeline the environment gets created on the fly. A custom domain name is even assigned by the branch name and is sent to the developer when ready for use. This tool, probably more than any other, changed the way we develop software. Furthermore, the technology driving these environments opened the door to our custom microservices platform and many more capabilities.
One last set of tools I will mention as it relates to our continuous delivery transformation is the metrics systems. In order
to optimize for time to detect we needed more visibility into the impact of our changes. This led to the installation of many tools,
including, Graphite with Grafana, LogStash/ElasticSearch/Kibana, NewRelic, and many others. We started to track metrics from all
over the place and had dashboards for all sorts of activities. 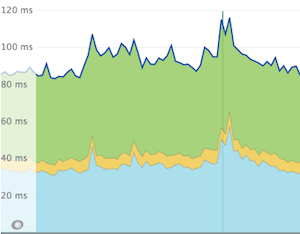 Events were tracked for various changes and shown on graphs giving us a more clear picture, like the one pictured from NewRelic where the
vertical line is marking a deployment. The dashboards people started to develop were amazing. Everyone completely embraced the
metrics systems and were tracking things we never thought to track before. New tools were developed
(GSampler for example) and alerts and monitors put in place to track the metrics.
The real power to this increased visibility was the ownership people started to feel over their changes. Dashboards
added this sense of transparency for everyone to see. We found that dev teams kept closer watch on their areas and were
quick to react to variances in the metrics.
Events were tracked for various changes and shown on graphs giving us a more clear picture, like the one pictured from NewRelic where the
vertical line is marking a deployment. The dashboards people started to develop were amazing. Everyone completely embraced the
metrics systems and were tracking things we never thought to track before. New tools were developed
(GSampler for example) and alerts and monitors put in place to track the metrics.
The real power to this increased visibility was the ownership people started to feel over their changes. Dashboards
added this sense of transparency for everyone to see. We found that dev teams kept closer watch on their areas and were
quick to react to variances in the metrics.
In the end…
As it is today, incidents are down, velocity is high, and teams are working independently. Each team can push to production more or less when they want. We have fully embraced the continuous work flow, which is now spread far and wide across our organization and ingrained in our microservices platform, tools, and culture. Back in 2011 we deployed the main website 6-9 times in a year. Last year in 2017 that same code base deployed roughly 1300 times to production. Taking into account our 100+ microservices we are running today we had nearly 5300 continuous deployments to production in 2017. It is nice, but our work is not complete. We are still learning and improving. Everyday there are adjustments and improvements made to our tools and our process. Additionally, there are still some dependencies and some amount of test instability to work through. Just par for the coarse and something to continue to iterate on.





